Predictive Maintenance Using AI: The UK SME Roadmap
Table of Contents
Unplanned machinery failure costs UK manufacturers an estimated £180 billion a year in lost production. Predictive maintenance using AI addresses this directly: instead of waiting for a breakdown or following a fixed servicing calendar, sensors and machine learning models flag problems before they become failures.
This guide covers how the technology works, which AI models drive the predictions, how to apply it to the legacy equipment common in British factories, and what the business case looks like for UK SMEs navigating Net Zero targets and HSE obligations.
You will find a practical five-step implementation roadmap, a plain-English breakdown of the four maintenance maturity levels, and answers to the questions engineers and operations managers ask most often.
What Is Predictive Maintenance and Why Does It Matter?

Most factories operate on one of two maintenance philosophies: fix it when it breaks, or service it on a fixed schedule. Both carry hidden costs. AI-driven predictive maintenance offers a third path, one grounded in the actual condition of your assets rather than guesswork or calendar dates.
Reactive, Preventive, and Predictive: The Key Differences
Reactive maintenance (run-to-failure) minimises upfront spending but creates unpredictable, expensive emergencies. A compressor that fails mid-shift can halt an entire production line, with the cost of emergency parts and overtime labour far exceeding what planned intervention would have cost.
Preventive maintenance replaces or services components on a fixed cycle, typically based on the manufacturer’s recommendation. The problem is that roughly 30% of components serviced this way still have significant life remaining. You are paying for maintenance you did not need.
Predictive maintenance is condition-based: sensors continuously monitor vibration, temperature, acoustic emissions, and electrical load. Machine learning models analyse that data stream and alert your team only when readings move outside normal parameters, which means maintenance happens exactly when it is needed.
The Four Levels of Maintenance Maturity
Understanding where your operation sits on the maturity scale helps set realistic expectations for an AI rollout.
Level 1 (Visual and Manual): Technicians inspect equipment by sight, sound, and touch. There is no digital data capture, and issues are caught only when they are already visible. Most small manufacturers start here.
Level 2 (Condition Monitoring): Basic sensors measure vibration or temperature at set intervals. Readings are logged but analysed retrospectively, often in a spreadsheet. Trends are visible in hindsight, but alerts are rarely automated.
Level 3 (Predictive Monitoring): Continuous sensor data feeds into a platform that uses statistical models or machine learning to detect early-warning patterns. Alerts are generated automatically, giving maintenance teams time to plan a response before a failure occurs.
Level 4 (Prescriptive Maintenance): The most advanced tier. AI not only predicts that a component will fail but also recommends the specific corrective action, models the downstream production impact of different intervention timings, and updates its recommendations as conditions change. This is where digital twin technology plays a significant role.
The majority of UK SMEs that are adopting AI currently sit between Levels 2 and 3. Moving to Level 4 requires a higher volume of quality historical data and usually a dedicated data engineering resource, though cloud-based platforms are steadily lowering that bar. You can read more about how SMEs are implementing AI solutions across different operational contexts.
A Maintenance Comparison at a Glance
The table below summarises the four strategies across the dimensions that matter most to a manufacturing SME.
| Strategy | Trigger | Failure Risk | Cost Profile | AI Involvement |
|---|---|---|---|---|
| Reactive | Breakdown | High | Unpredictable, often high | None |
| Preventive | Fixed schedule | Medium | Predictable, sometimes wasteful | None to low |
| Predictive | Sensor readings | Low | Optimised, targeted | Medium to high |
| Prescriptive | AI recommendation | Very low | Highly optimised | Full integration |
How the AI Tech Stack Works: From Sensor to Insight
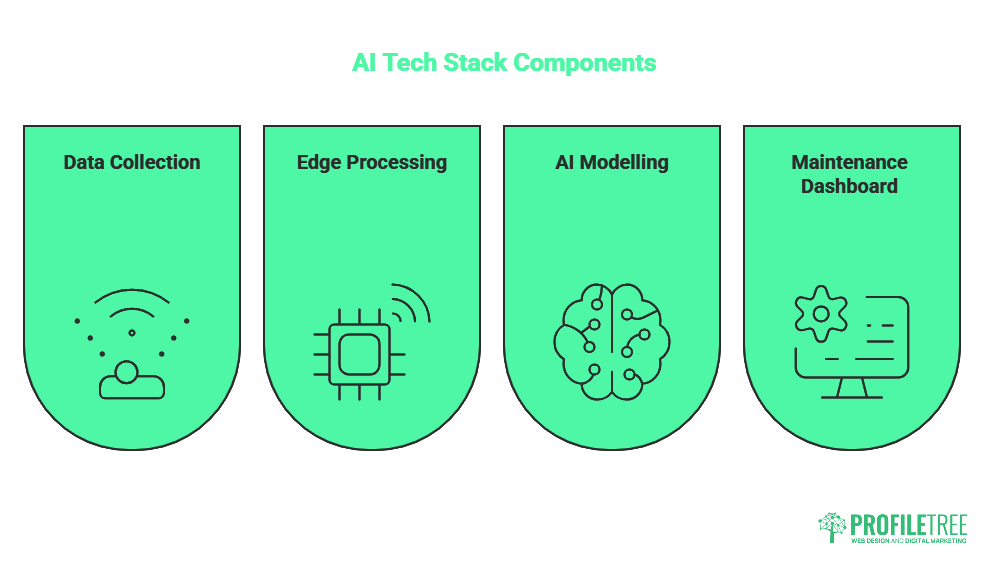
A predictive maintenance system has four distinct layers. Understanding each one helps you identify where your current infrastructure already delivers value and where the genuine gaps are.
Data Collection: The Sensor Layer
Sensors are the starting point. The most widely used types in UK manufacturing environments include vibration sensors mounted to rotating machinery such as motors, pumps, and gearboxes; thermal imaging cameras or thermocouples that detect heat anomalies in electrical cabinets and bearings; acoustic emission sensors that pick up high-frequency stress waves caused by cracks or friction; and current and power quality monitors attached to drive systems.
Modern sensors can transmit wirelessly via industrial Bluetooth or low-power wide-area networks (LPWAN), which is significant for brownfield sites where running new data cabling would be prohibitively disruptive. Sampling rates vary by asset criticality: a high-speed turbine might generate data every millisecond, while a slow-moving conveyor belt may only need readings every few minutes.
Edge Processing and Data Transmission
Raw sensor data is enormous. Edge gateways, small computing units installed near the machinery, pre-process and filter this data before sending only the relevant readings to the cloud or on-premises server. This reduces bandwidth costs and means that time-critical alerts can be acted on locally without depending on an internet connection.
The processed data then feeds into a central platform, which could be a cloud service such as Microsoft Azure IoT Hub, AWS IoT Greengrass, or a specialist industrial platform, where it is stored, labelled, and made available for model training and live inference.
AI Modelling and Anomaly Detection
This is where machine learning takes over. Models are trained on historical sensor data, ideally including records of past failures, to learn what normal operation looks like for each asset. Once deployed, they run continuously, comparing incoming readings against that baseline and flagging deviations. You can explore the advanced machine learning techniques that underpin these systems in more detail.
The specific AI models used are covered in depth in the next section.
The Maintenance Dashboard
Alerts and predictions surface in a dashboard accessible to maintenance managers, engineers, and operations leads. Good platforms present not just the alert but a confidence score, the likely root cause, the recommended action, and an estimated time to failure. The goal is to give a technician enough information to make a prioritised decision, not just an alarm to acknowledge.
Core AI Models Used in Predictive Maintenance
The choice of algorithm depends on the nature of the asset, the volume of historical data available, and the type of failure you are trying to predict. No single model works universally well, and in practice, most commercial platforms blend several approaches.
Anomaly Detection Models
These models establish a statistical envelope around normal operating behaviour and raise alerts when readings fall outside it. Isolation Forest and One-Class SVM are widely used for this purpose because they can be trained on normal data alone, without needing labelled examples of failures. That is valuable in manufacturing, where genuine failures are often rare enough that there is not enough historical data to train a supervised classifier.
Autoencoder neural networks take a different approach: they learn to compress and reconstruct normal sensor data and flag high reconstruction errors as anomalies. Autoencoders work particularly well on multivariate time-series data where multiple sensors interact in complex ways.
Remaining Useful Life (RUL) Estimation
Where anomaly detection tells you something is wrong, RUL estimation tells you roughly how long you have left. Long Short-Term Memory (LSTM) networks are the most commonly applied architecture here. LSTMs are a form of recurrent neural network that can learn patterns across long time sequences, which makes them well-suited to degradation curves that develop over hundreds of operating hours.
Gradient Boosting models, such as XGBoost, are an alternative for operations with structured tabular data and limited computational infrastructure. They are faster to train, more interpretable, and perform competitively on smaller datasets compared to deep learning approaches.
Random Forests for Fault Classification
When you have enough labelled failure data, Random Forest classifiers can categorise faults by type. Rather than just detecting that something has changed, the model can distinguish between, for example, bearing wear, imbalance, and misalignment in a rotating machine. This makes the maintenance recommendation much more specific and reduces diagnostic time on the shop floor.
The quality of your training data matters enormously here. A well-labelled dataset of 500 real fault examples will outperform a poorly labelled dataset of 50,000 records. As Ciaran Connolly, founder of ProfileTree, puts it: “The companies that see the best returns from AI in their operations are not the ones with the most data. They are the ones that have invested in understanding what their data actually means.”
The Brownfield Challenge: Applying AI to Legacy Machinery
The majority of manufacturing SMEs in the UK and Ireland operate what is known as brownfield environments: factories with a mix of machine ages, often spanning 10 to 30 years, running proprietary control systems, and with little or no existing sensor infrastructure. The global technology vendors who dominate the predictive maintenance market largely assume you are starting fresh. The reality for most British manufacturers is quite different.
Retrofitting Sensors to Older Assets
The good news is that modern non-invasive sensors can be attached to most machinery without modification. Magnetic-mount vibration sensors clamp directly onto motor housings or gearbox casings. Thermal cameras mounted above process lines require no physical contact with the equipment. Current transformers clip around power cables to monitor electrical load. None of these requires the machine to be taken out of service for installation.
The main technical challenge is data labelling: if a machine has been running without digital monitoring for 15 years, there is no historical sensor data to train a model on. The standard approach is to run a monitoring-only phase of three to six months first, capturing baseline data before any AI model is deployed. This gives the system enough context to establish what normal looks like. You can read more about integrating AI with existing systems in older infrastructure environments.
Legacy Control Systems and Data Extraction
Many older CNC machines, PLCs, and SCADA systems store operational data in proprietary formats or communicate over legacy protocols like Modbus or OPC-DA. Extracting this data for use in modern AI platforms typically requires a protocol converter or an industrial IoT gateway that translates legacy formats into standard outputs. Several UK-based systems integrators specialise precisely in this bridging work.
Where it is not possible to extract data from the control system directly, standalone sensor networks are the answer. These operate entirely independently of the machine’s existing electronics and therefore work regardless of how old or proprietary the underlying control architecture is.
The Pilot Asset Approach
One of the most common mistakes in brownfield deployments is attempting a site-wide rollout from day one. A factory with 80 machines does not need 80 machines monitored simultaneously in year one. Start with a single critical asset, preferably one with a known failure history, and build the data collection and alerting workflow around that machine first. Once the process is proven and the team is comfortable with the platform, expansion is straightforward. Overcoming AI adoption challenges is significantly easier when the scope is kept tight at the outset.
The UK Business Case: ROI, HSE Compliance, and Net Zero
For predictive maintenance to earn a budget allocation, it needs to stack up financially. It also needs to connect to the compliance and sustainability obligations that UK manufacturers now face. The business case has three distinct dimensions.
The Financial Return
Published benchmarks from the manufacturing sector suggest that well-implemented predictive maintenance programmes reduce unplanned downtime by 20 to 40% and cut overall maintenance costs by 10 to 25%. For a mid-sized UK manufacturer spending £500,000 a year on maintenance and losing the equivalent of £200,000 in unplanned downtime, the combined saving could reach £150,000 annually. All prices and figures in this guide are indicative UK examples and correct at the time of writing; use them as a benchmark rather than fixed quotations.
The return on investment case is also shifting structurally. Many predictive maintenance platforms are now priced on a software-as-a-service model, moving the cost from a capital expense to an operational one. That makes it easier to justify internally and removes the need for large upfront hardware procurement. For a detailed breakdown of how to build this case, the cost-benefit analysis of AI for SMEs provides a practical framework.
HSE Compliance and Worker Safety
The Health and Safety Executive’s guidance on machinery safety is explicit: employers must take reasonably practicable steps to prevent equipment failures that could harm workers. A machine running with a degraded bearing or electrical fault that goes undetected is a compliance risk, not just an operational one.
Predictive maintenance systems generate a continuous audit trail of equipment condition. If an incident does occur, that data log demonstrates that monitoring was in place and alerts were acted on, which is material evidence in any HSE investigation. For industries with specific sector regulations, such as food processing, pharmaceutical manufacturing, or chemical production, the audit capability is especially valuable.
Net Zero and the Sustainability Case
The connection between predictive maintenance and the UK’s Net Zero 2050 commitment is underappreciated. Machinery operating outside its optimal condition uses more energy. A motor running with bearing wear draws higher current. A heat exchanger fouled with deposits transfers heat less efficiently. An AI maintenance system that keeps assets running at peak efficiency is, by extension, an energy efficiency tool.
Extended asset life also reduces the embodied carbon cost of manufacturing new replacement components and the waste from discarding parts with remaining useful life. For UK manufacturers required to report Scope 1 and Scope 2 emissions, the energy savings from optimised maintenance are directly measurable and reportable.
The overlap between AI technology and environmental goals is explored further in ProfileTree’s article on AI and sustainability in business operations. If you are looking for broader inspiration on what industries thrive when operating sustainably in the UK and Ireland, Northern Ireland’s manufacturing and tourism sectors offer a compelling regional example.
Five-Step Implementation Roadmap for UK SMEs
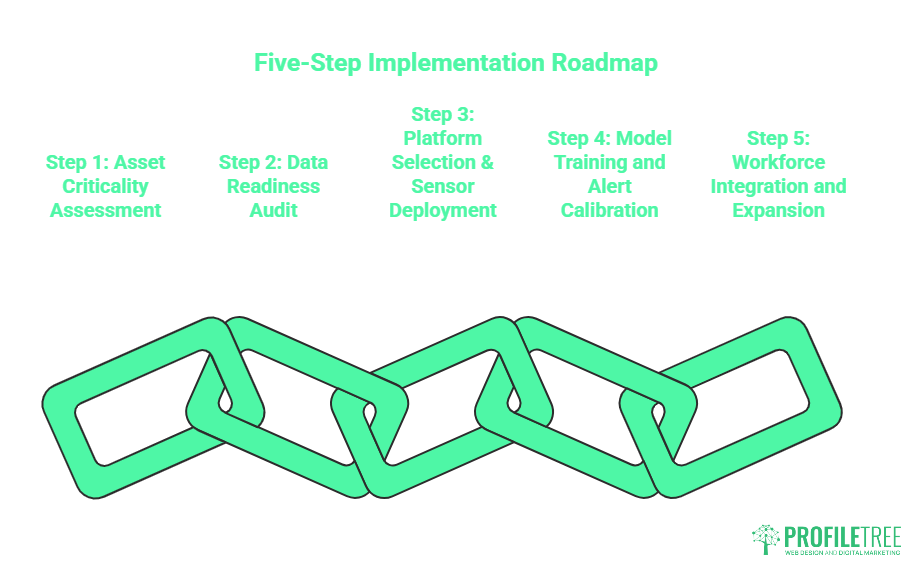
There is no universal deployment template for predictive maintenance, but the following framework reflects the approach that consistently produces measurable results for mid-market manufacturers. Each step is designed to be completed before the next begins.
Step 1: Asset Criticality Assessment
List every piece of production equipment and rank it by two factors: the production impact of its failure and the historical frequency of its maintenance issues. This produces a prioritised list. The machine at the top is your pilot asset. Avoid the temptation to start with the newest machine because the data is cleaner; start with the one where a failure costs the most.
Step 2: Data Readiness Audit
Before purchasing any platform, assess what data you can actually collect from the pilot asset. Document the sensor types available, the communication protocols in use, the sampling rates achievable, and any gaps in historical maintenance records. This audit determines whether you need additional hardware investment and sets realistic expectations for model training timelines. The importance of this foundational step is detailed in our guide on data in AI implementation.
Step 3: Platform Selection and Sensor Deployment
With the data audit complete, select a platform matched to your infrastructure. Cloud-based solutions from vendors such as Uptake, Seeq, or IBM Maximo Application Suite each have different strengths: Seeq is particularly well-regarded for process manufacturing, while IBM Maximo is stronger in asset-intensive heavy industry. Install sensors on the pilot asset and allow the data collection phase to run for at least eight weeks before attempting to train any predictive model.
Step 4: Model Training and Alert Calibration
Once a sufficient baseline dataset exists, work with your platform provider or internal data team to train the initial anomaly detection or RUL model. The first version will not be perfect. Alert calibration is the critical activity at this stage: too many false positives and maintenance teams stop responding to alerts; too few, and genuine faults are missed. Expect to iterate on thresholds for the first two to three months. Real-time analytics with AI explains the monitoring processes that sit behind this calibration work.
Step 5: Workforce Integration and Expansion
Technology adoption in manufacturing lives or dies on the shop floor. Maintenance technicians who understand what the AI is measuring, why it is alerting, and how to act on those alerts are the difference between a system that generates value and one that gets ignored.
Structured training for maintenance staff is not optional; it is part of the deployment. Once the pilot is stable and the team is confident, expand to the next priority assets. You can find practical guidance on training your team to work effectively alongside AI tools.
The Human Element: Upskilling Your Maintenance Workforce
One of the most consistent gaps in the predictive maintenance literature is the treatment of maintenance staff as passive recipients of AI recommendations. The technology produces better outcomes when the engineers who know the machines are involved in shaping and validating the models.
From Reactive Technician to Data-Informed Engineer
The role of a maintenance technician in a predictive maintenance environment changes considerably. Rather than waiting for breakdowns or working through a service checklist, technicians spend more time reviewing sensor trends, investigating early warnings, and feeding their domain knowledge back into the platform. A technician who has maintained the same pump for eight years knows nuances about its behaviour that no dataset captures.
This shift requires a different skill set, not a replacement of the existing one. Training tends to focus on three areas: understanding what the sensors measure and what anomalies look like in the data; using the maintenance platform dashboard effectively; and applying the AI’s recommendations critically rather than blindly. The goal is augmented intelligence, not automated replacement.
Managing the Cultural Transition
Resistance to AI tools in manufacturing often has less to do with the technology and more to do with how it is introduced. If maintenance staff perceive the system as a performance monitoring tool rather than a support tool, adoption suffers. The framing matters: the AI handles continuous monitoring so that technicians can focus on the diagnostic and corrective work that requires physical skill and judgement.
Senior engineers who act as internal champions for the system, rather than having it managed entirely by an external vendor or IT team, produce faster adoption cycles and better model calibration. Implementing AI without a huge investment is genuinely achievable when the human change management side is given equal weight to the technical deployment.
Conclusion
Predictive maintenance using AI moves UK manufacturers from reactive firefighting to data-driven decision-making. The technology is no longer confined to large enterprises: affordable sensors, cloud-based platforms, and proven implementation frameworks make it accessible to SMEs with legacy equipment and modest data infrastructure. The business case is clear across cost reduction, HSE compliance, and Net Zero alignment. The next step is an asset criticality assessment and a realistic data readiness audit.
If your operation is ready to move beyond scheduled servicing and into condition-based asset management, explore our digital training services or get in touch to discuss where to start.
FAQs
What is the difference between predictive and preventive maintenance?
Preventive maintenance services equipment on a fixed calendar schedule regardless of its actual condition. Predictive maintenance is condition-based: sensors monitor assets continuously and trigger action only when the data indicates a genuine need. This avoids both the emergency costs of reactive failure and the wasted spend of over-servicing.
What AI algorithms are best for predictive maintenance?
Isolation Forest and autoencoder networks work well for anomaly detection, while LSTM networks are the standard choice for remaining useful life estimation. Random Forest classifiers are effective when labelled historical fault data is available. Most commercial platforms blend several methods rather than relying on a single algorithm.
How much data do I need before AI can be useful?
Anomaly detection models can generate useful alerts after just four to eight weeks of baseline sensor data, since they only need to learn what normal operation looks like. Supervised fault-classification models require more labelled failure examples. Starting data collection early, before committing to a platform, is the fastest route to reliable predictions.
How does predictive maintenance contribute to UK Net Zero goals?
Machinery in a degraded state draws more energy than equipment running at its design parameters, so keeping assets in optimal condition directly cuts Scope 1 emissions. Extended asset life also reduces the embodied carbon cost of producing and disposing of replacement components. For businesses subject to UK energy and carbon reporting, the efficiency gains are directly measurable.
Can AI maintenance work on old legacy equipment?
Yes. Non-invasive sensors such as magnetic-mount vibration monitors and clip-on current transformers retrofit to most machinery without modification or downtime. The main hurdle is the absence of historical sensor data, requiring a monitoring-only phase of several months before model training begins. Protocol converters bridge legacy control systems to modern cloud platforms in the majority of cases.